Data Warehouses vs Data Lakes vs Data Lakehouses: Understanding Modern Data Architectures on AWS
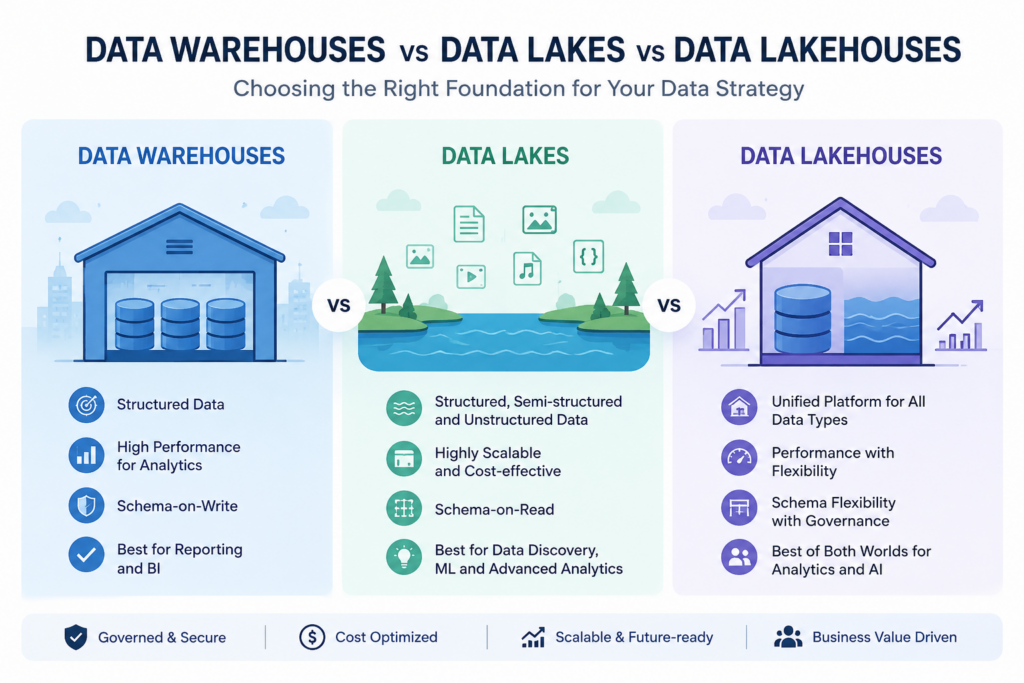
As organizations continue generating massive amounts of data from applications, customer interactions, IoT devices, and digital platforms, managing that data efficiently has become one of the biggest challenges in modern cloud computing.
For data engineers, AI practitioners, and cloud architects, understanding the differences between Data Warehouses, Data Lakes, and Data Lakehouses is essential. These architectures form the backbone of analytics, business intelligence, and machine learning systems across enterprises today.
In this blog, we’ll explore:
- What data warehouses are
- How data lakes differ
- Why data lakehouses are gaining popularity
- Key AWS services involved
- Real-world use cases
- When to choose each architecture
The Evolution of Data Architectures
Traditionally, businesses relied heavily on structured relational databases for reporting and analytics. However, with the explosion of unstructured and semi-structured data, organizations needed more flexible and scalable storage solutions.
This evolution led to three major architectural approaches:
- Data Warehouse – Optimized for structured analytics
- Data Lake – Built for raw and flexible data storage
- Data Lakehouse – A hybrid approach combining both worlds
What Is a Data Warehouse?
A Data Warehouse is a centralized repository optimized for analytics and reporting. It stores data from multiple sources in a highly structured format.
The core idea behind a data warehouse is:
- Clean the data
- Transform the data
- Structure the data
- Optimize it for querying
This process is commonly known as ETL (Extract, Transform, Load).
Key Characteristics of Data Warehouses
Structured Data
Data warehouses work best with:
- Relational data
- Tabular formats
- Predefined schemas
Optimized for Analytics
Designed specifically for:
- Complex SQL queries
- Reporting dashboards
- Business intelligence workloads
Read-Heavy Systems
They prioritize fast query performance over frequent updates.
Schema-on-Write
The schema is defined before data is stored.
This means:
- Data must be transformed before loading
- Structure is enforced upfront
AWS Services for Data Warehousing
The flagship AWS service for data warehousing is:
- Amazon Redshift
Other cloud equivalents include:
- Google BigQuery
- Azure Synapse Analytics
But for AWS-focused architectures, Redshift remains the primary choice.
Real-World Example of a Data Warehouse
Imagine an e-commerce company collecting:
- Clickstream data
- Purchase transactions
- Product catalog information
All this data is cleaned and transformed before loading into a centralized warehouse.
Different departments may then create specialized data marts:
- Finance dashboards
- Customer behavior analytics
- Machine learning datasets
- Recommendation systems
This enables high-performance analytics across the organization.
What Is a Data Lake?
A Data Lake is a massive storage repository that stores raw data in its native format.
Unlike data warehouses, data lakes:
- Do not require predefined schemas
- Accept structured, semi-structured, and unstructured data
- Prioritize flexibility and scalability
The philosophy is simple:
“Store first, analyze later.”
Key Characteristics of Data Lakes
Schema-on-Read
The schema is applied only when data is queried.
This means:
- Raw data is stored immediately
- Transformations happen later
Supports All Data Types
Data lakes can store:
- JSON
- XML
- Images
- Videos
- Logs
- Sensor data
- CSV files
- Structured databases
Highly Scalable
Perfect for petabyte-scale storage.
Cost Effective
Object storage systems make data lakes affordable.
AWS Services for Data Lakes
The most common AWS data lake architecture uses:
- Amazon S3 as storage
- AWS Glue for schema discovery
- Amazon Athena for querying
- AWS Lake Formation for governance
These services together create a highly scalable and flexible data ecosystem.
ETL vs ELT: The Fundamental Difference
One of the biggest distinctions between data warehouses and data lakes lies in how data is processed.
Data Warehouse → ETL
Extract → Transform → Load
Data is:
- Extracted
- Cleaned and transformed
- Loaded into structured storage
This ensures optimized performance and consistency.
Data Lake → ELT
Extract → Load → Transform
Data is:
- Extracted
- Stored immediately in raw format
- Transformed later when needed
This provides:
- Greater flexibility
- Faster ingestion
- Easier experimentation
Data Warehouse vs Data Lake
| Feature | Data Warehouse | Data Lake |
|---|---|---|
| Data Type | Structured | Structured + Unstructured |
| Schema | Schema-on-write | Schema-on-read |
| Processing | ETL | ELT |
| Performance | Optimized for analytics | Optimized for storage |
| Flexibility | Lower | Higher |
| Cost | Higher | Lower |
| Use Cases | BI & reporting | ML & exploratory analytics |
When Should You Use a Data Warehouse?
A data warehouse is ideal when:
- Data sources are structured
- Business reporting is critical
- Fast SQL analytics are required
- Data consistency is essential
- Enterprise dashboards are needed
Common use cases:
- Financial reporting
- Executive dashboards
- Operational analytics
- KPI monitoring
When Should You Use a Data Lake?
A data lake is better when:
- You have massive data volumes
- Data formats vary significantly
- You need machine learning pipelines
- You want long-term raw data storage
- Future analytics requirements are uncertain
Common use cases:
- AI/ML training datasets
- Log analytics
- IoT systems
- Behavioral analytics
- Data science experimentation
What Is a Data Lakehouse?
A Data Lakehouse combines the strengths of both data warehouses and data lakes.
It aims to provide:
- The scalability and low cost of data lakes
- The performance and reliability of data warehouses
This modern architecture supports:
- Structured and unstructured data
- Analytics and machine learning
- Schema-on-write and schema-on-read
- ACID transaction capabilities
Why Data Lakehouses Are Becoming Popular
Modern enterprises want:
- One unified platform
- Reduced data duplication
- Simplified architecture
- Better analytics + ML integration
Data lakehouses address these challenges by enabling direct analytics on raw cloud storage.
AWS Data Lakehouse Architecture
A common AWS lakehouse setup includes:
- Amazon S3 for raw storage
- AWS Lake Formation for management
- Amazon Redshift Spectrum for analytics
Here:
- Data remains in S3
- Redshift Spectrum queries the data directly
- No need to move data into a separate warehouse
This creates a hybrid architecture combining flexibility with analytics performance.
The Future of Data Platforms
The industry is steadily moving toward:
- Unified analytics platforms
- Cloud-native architectures
- AI-driven data ecosystems
- Real-time processing systems
Data lakehouses are emerging as the preferred architecture because they reduce silos and simplify modern analytics workflows.
For machine learning engineers, understanding these architectures is essential because data quality, accessibility, and scalability directly impact AI performance.
Final Thoughts
Choosing between a Data Warehouse, Data Lake, or Data Lakehouse depends entirely on your business requirements.
- Use a Data Warehouse for structured analytics and reporting.
- Use a Data Lake for flexible, large-scale raw data storage.
- Use a Data Lakehouse when you need both analytics and machine learning on a unified platform.
In modern AWS environments, organizations increasingly use a combination of these architectures to build scalable and intelligent data ecosystems.
As cloud technologies evolve, mastering these concepts becomes critical for data engineers, architects, and AI professionals preparing for the next generation of enterprise data platforms.