In a linear regression model defined as:Y=b0+b1X1
where Y represents salary and X1 represents years of experience, I would like to understand why Euclidean distance (or Euclidean error calculation) is used in the model.
Assumption is that salary growth in real-world scenarios may not always be linear and could instead grow exponentially with experience. Because of this non-linear relationship, the linear regression model may produce inaccurate or inconsistent prediction results. Is this the reason why the Euclidean error calculation becomes significant in such cases?
In a simple linear regression model:Y=b0+b1X1
where:
- Y = Salary
- X1 = Years of Experience
- b0 = intercept
- b1 = slope (salary increase per year)
the Euclidean calculation appears because the model tries to measure how far the predicted salary is from the actual salary.
The key idea is:
Linear regression finds the “best fit line” by minimizing prediction errors.
Those errors are measured using Euclidean distance principles.
Why Euclidean Distance Appears
Suppose you have actual salary data:
| Experience | Actual Salary |
|---|---|
| 2 | 5 LPA |
| 4 | 8 LPA |
| 6 | 11 LPA |
The model predicts salaries using the line:Y^=b0+b1X
For each point, there is an error:Error=Y−Y^
Linear regression minimizes the total squared error:∑(Y−Y^)2
This comes directly from Euclidean geometry.
Geometric Meaning
Each data point exists in space.
For example:
- (2, 5)
- (4, 8)
- (6, 11)
The regression line tries to stay as close as possible to all points.
The “distance” from a point to the line is based on Euclidean distance.
In 2D geometry:Euclidean Distance=(x2−x1)2+(y2−y1)2
Regression simplifies this by mostly minimizing the vertical distance between actual and predicted values.
Why Squared Error Is Used
Instead of absolute distance:∣Y−Y^∣
regression uses squared distance:(Y−Y^)2
because:
- It penalizes large errors more heavily
- It is mathematically differentiable
- Optimization becomes easier using calculus
This method is called:
Ordinary Least Squares (OLS)
Your Assumption About Exponential Salary Growth
You are partially correct.
You mentioned:
salary increases exponentially
That can indeed create problems for simple linear regression.
A linear model assumes:Salary increases at a constant rate
Meaning:
- every additional year adds roughly the same salary increment.
Example:
| Experience | Salary |
|---|---|
| 1 | 4 |
| 2 | 5 |
| 3 | 6 |
This is linear.
But real-world salaries often grow non-linearly:
| Experience | Salary |
|---|---|
| 1 | 4 |
| 5 | 10 |
| 10 | 30 |
| 15 | 70 |
This is closer to exponential growth.
A straight line cannot fit such data properly.
That leads to:
- large residual errors
- inaccurate predictions
- high Euclidean distances
- poor model fit
Why the Model Gives “Erratic” Results
Because the model assumptions are violated.
Linear regression assumes:
- Linear relationship
- Constant variance
- Independent observations
- Normally distributed residuals
If salary grows exponentially:Y=b0+b1X
then residuals become large and uneven.
The optimization still minimizes Euclidean-based squared errors, but the line becomes a poor representation of the data.
Better Models for Salary Growth
Instead of linear regression, you may use:
Polynomial Regression
Y=b0+b1X+b2X2
Useful when growth curves upward.
Logarithmic / Exponential Models
If salary grows exponentially:Y=aebx
or transform data:log(Y)=b0+b1X
Tree-Based ML Models
Such as:
- Random Forest
- XGBoost
- Gradient Boosting
These capture non-linear patterns much better.
Visual Intuition
Linear regression tries to fit:
y=b0+b1x
But if real salary growth behaves more like:
y=aebx
a
b
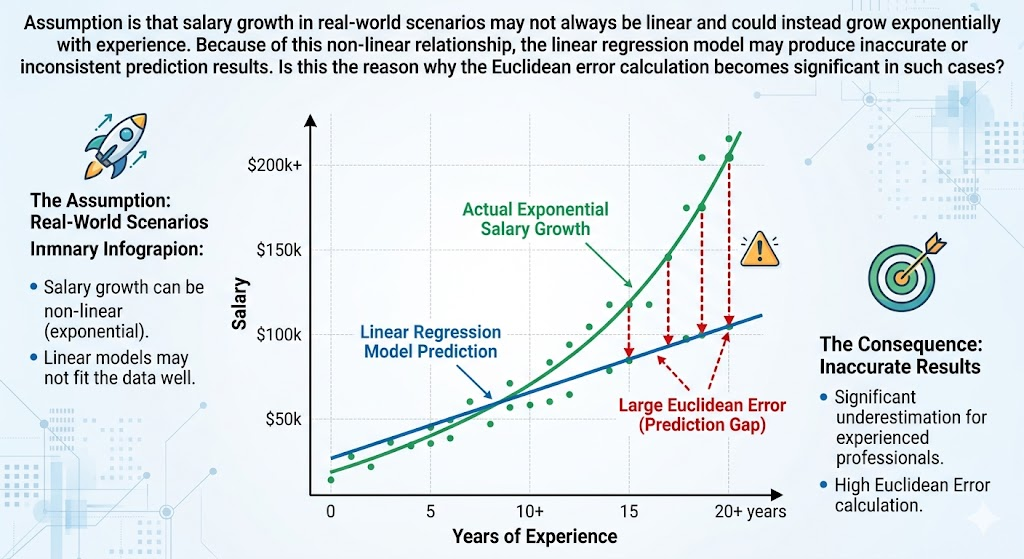
then the straight line creates large Euclidean residual distances.
Final Summary
Euclidean calculation appears in linear regression because:
- the algorithm measures prediction error as geometric distance,
- specifically squared Euclidean distance,
- and minimizes total error using Least Squares.
Your intuition is also correct that:
- if salary growth is exponential/non-linear,
- simple linear regression performs poorly,
- causing large residual errors and unstable predictions.
In such cases, non-linear models work better.